
In the early days of GitLab.com, most of the application, including Rails worker processes, Sidekiq background processes, and Git storage, all ran on a single server. A single server is easy to deploy to and maintain. The same structure is what most smaller GitLab instances still use for their self-managed Omnibus installation. Scaling is done vertically, meaning; adding more RAM, CPU, and disk space.
Moving from vertical to horizontal scaling
Soon we ran out of options to continue scaling the system vertically, and we had to move to scaling horizontally by adding new servers. To have the repositories available on all the nodes, NFS (Network File System) was used to mount these to each application server and background workers. NFS is a well-known technology for sharing file systems across a network. For each server, each storage node needed to be mounted. The advantage: GitLab.com could keep adding more servers and scale. However NFS had multiple disadvantages too: the visibility is decreased to what type of file system operation is performed. Even worse, one NFS storage node's outage impacted the whole site, and took the whole site down. On the other hand, Git operations can be quite CPU/IOPS intensive too, so we began a balancing act between adding more nodes, and thus reducing reliability, versus scaling nodes vertically.
Considering NFS alternatives
Over two years ago, we started to look for alternatives. One of the first ideas was to remove the dependency on NFS with Ceph. Ceph is a distributed file system that was meant to replace NFS in an architecture like ours. Like NFS, this would solve our scaling problem on the system level, meaning that little to no changes would be required to GitLab as an application. However, running a Ceph cluster in the cloud didn't have the performance characteristics that were required. Briefly we flirted with the idea of moving away from the cloud, but this would have had major implications for our own infrastructure team, and given that many of our customers do run in the cloud, we decided to stay in the cloud.
Introducing Gitaly
So it was clear that the application needed to be redesigned, and a new service would be introduced to handle all Git requests. We named it Gitaly.
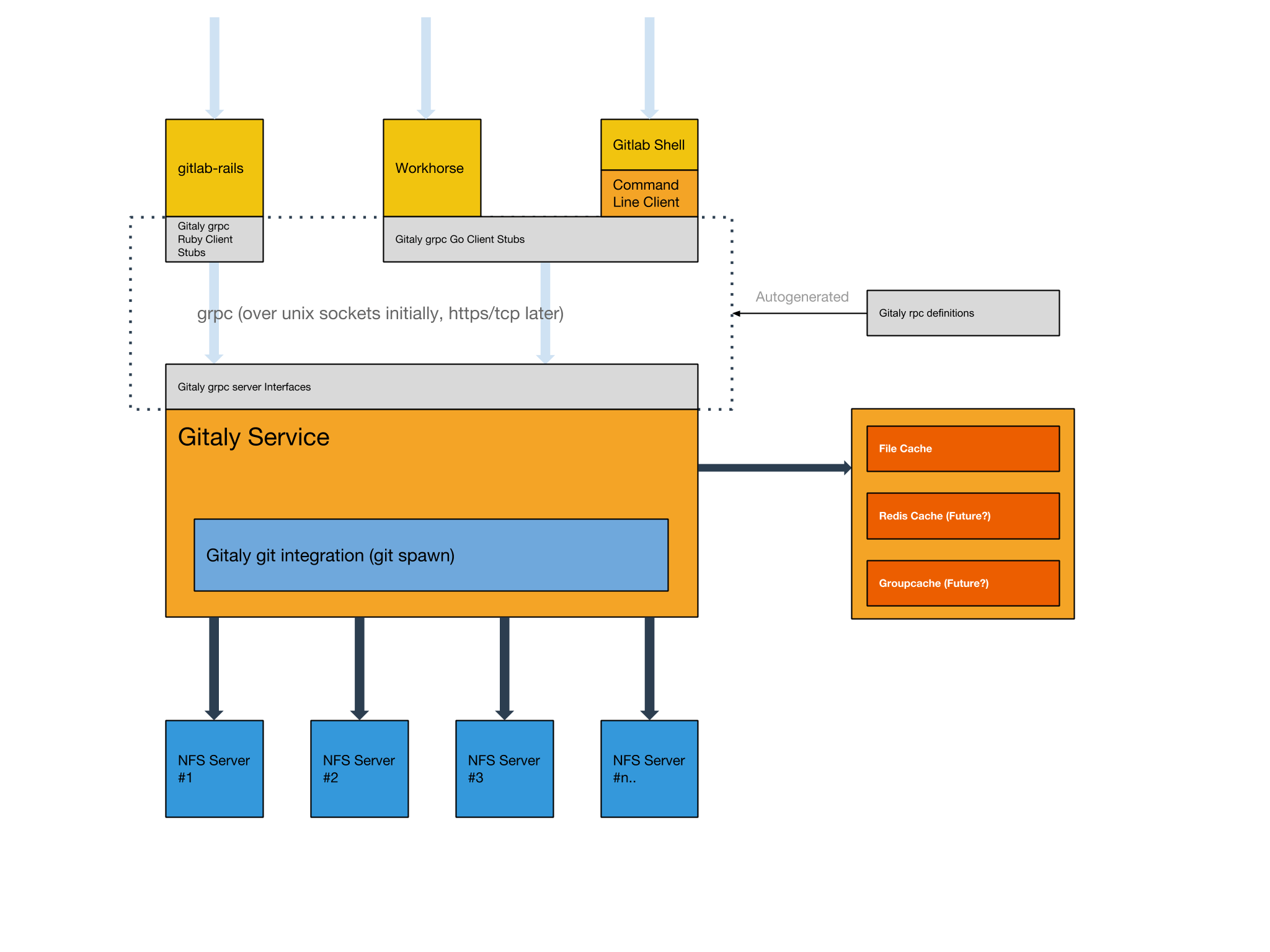 The planned architecture at the project start
The planned architecture at the project start
As the diagram shows, the new Git server would have a number of distinct clients. To make sure the protocol for the server and its clients is well defined, Protocol Buffers was used. The client calls are handled by leveraging gRPC. Combined, they allowed us to iteratively add RPCs and move away from NFS, in favor of an HTTP boundary. With the technologies chosen, the migration started. The ultimate goal: v1.0, meaning no disk access was required to the Git storage nodes for GitLab.com.
Shipping such an architectural change should not influence the performance, nor the stability of the self-managed installations of GitLab, so for each RPC a feature flag gated the use of it. When the RPC had gone through a series of tests on both correctness and performance impact, the gate was removed. To determine stability we used Prometheus for monitoring and the ELK stack for sifting through massive numbers of structured log messages.
The server was written in Go, while the application is a large Rails monolith.
Rails had a great amount of code that was still very valuable. This code got
extracted to the lib/gitlab/git directory, allowing easier vendoring. The idea
was to start a sidecar next to the Go server, reusing the old code. About once a week the
code would be re-vendored. This allowed Ruby developers on other teams to
write code once, and ship it. Bonus points could be earned if the boilerplate code
was written to call the same function in Ruby!
The new service wasn't all sunshine and rainbows though, at times it felt like the improved visibility was hurting our ability to ship. For example, it became clear that the illusion of an attached disk created N + 1 problems. And even though this is a well-known problem in Ruby on Rails, the tools to combat it are all tailored toward using it with ActiveRecord, Rails' ORM.
Nearing v1.0
With each RPC introduced, v1.0 was getting closer and closer. But how could we be sure everything was migrated before unmounting all NFS mount points? A trip switch got introduced, guarding the details required to get to the full path of each repository. Without this data there was no way to execute any Git operation through NFS. Luckily, the trip switch never went off, so now it was clear NFS wasn't being used. The next step was unmounting on our staging environment! Again, this was very uneventful. Leaving the volumes unmounted for a full week, and not seeing any indication of unexpected errors, the logical next step was our production instance.
Days later we started rolling out these changes to production: first the background workers were unmounted, than we moved onto higher impact services. At the end of the day, all drives were unmounted without customer impact.
What's next?
So, where is this v1.0 tag? We didn't tag it, and I don't think we will. v1.0 is a state for our Git infrastructure, and a goal for the team, rather than the code base. That being said, the next mental goal is allowing all customers to run without NFS. At the time of writing, some features like administrative tasks, aren't using Gitaly just yet. These are slated for v1.1, and our next objective.
Want to know more about our Gitaly journey? Read about how we're making your Git data highly available with Praefect and how a fix in Go 1.9 sped up our Gitaly service by 30x.
Photo by Jason Hafso on Unsplash


